并发服务实现
最近拜读了Eli Bendersky写的Concurrent Servers系列博客,作者由简单到复杂,由串行到并行,由多线程到事件驱动,再到第三方库对并发的实现,梳理了并发服务相关思想,在此对相关重点做一总结。
作者写就此文的目的是检验几种流行的并发模型,评判这些模型的伸缩性(scalability)和是否容易实现。作者自定义了一种简单的协议(protocol),用于服务端与客户端交互,协议是有状态的(stateful),服务端根据客户端发送的数据更改状态,并根据状态产生不同行为。
A sequential server
串行服务,一次只能处理一个客户端请求,其他客户端只能等待,所以效率很低,这也促使引入更高效的并发模型。(我之前的一篇博客网络连接为什么超时了就跟串行服务有关)
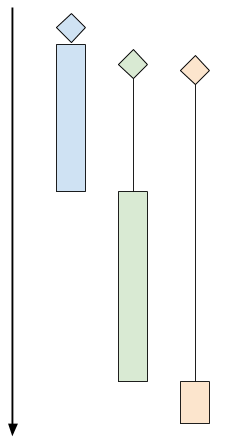
Threads
并发实现的一种方法是多线程,这样服务端可同时处理多个客户端。
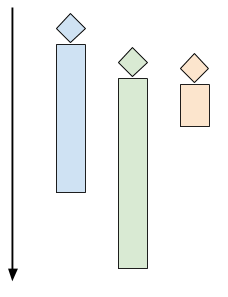
每一个客户端都新建一个线程,带来的问题是,客户端一多,线程会占用服务器大量内存,而且大量CPU时间用于线程上下文切换,甚至会引发安全问题,资源耗尽造成拒绝服务(DoS)攻击。所以需要对并发的客户端数量进行限制(rate-limiting),比较流行的设计是线程池(thread pool)。
Thread pools
线程池思想简单,却功能强大。服务端创建一个有多个线程的线程池,只有线程池中有空闲线程时,才会处理新的客户端请求。在面对高负载时,线程池也是一种优雅降级(graceful degradation),服务端仍然能以一定速率提供正常服务,而不会资源耗尽停止服务。
Event driven
多线程并不是并发处理的唯一方式,另外一种常见的并发方法是事件驱动编程(event-driven programming),即异步编程(asynchronous programming)。
Blocking vs. nonblocking I/O
首先对比下阻塞I/O和非阻塞I/O,阻塞I/O是我们比较熟悉的I/O API工作方式,比如从一个socket接收数据,对recv的调用会阻塞,直到接收到数据。当把socket设置为非阻塞模式,对recv的调用会立即返回,即使没有接收到数据。
似乎我们可以通过非阻塞I/O来实现并发,同时处理多个客户端,只要轮询(polling)每个socket,检查是否收到了数据。但是在实际应用中,这种解决方案伸缩性较差,比如现在有1000个客户端需要并发处理,单单是遍历所有sockets就要花费很多时间,相当低效。其实操作系统内部是知道哪个socket收到了数据,我们不必扫描所有sockets,直接使用提供的API即可。
select
select允许在单线程中监控多个文件描述符,无需不必要的轮询。通过select,实现了I/O复用(I/O multiplexing),在同一个线程中并发处理多个客户端,一个客户端处理完一些工作后,就切换到另一个客户端接着处理。
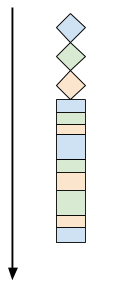
然而select有一定的限制,一是可监控的文件描述符数量受限,一般最多为1024,二是性能较差,当select返回时,提供的信息只有可用文件描述的数量,具体是哪些文件描述符可用,还是需要遍历所有监控的文件描述符。因此现代并发服务实现已经很少用select了,转而使用更高效的其他API,如epoll。
epoll
epoll的高效之处在于直接返回所有可用的文件描述符,不必再去遍历所有文件描述符,这样就将找到可用文件描述符的时间复杂度从O(N)降到了O(1)。
libuv
直接基于select或epoll实现并发服务,跨平台能力较差,libuv做了一层抽象,提供高性能异步IO编程模型。
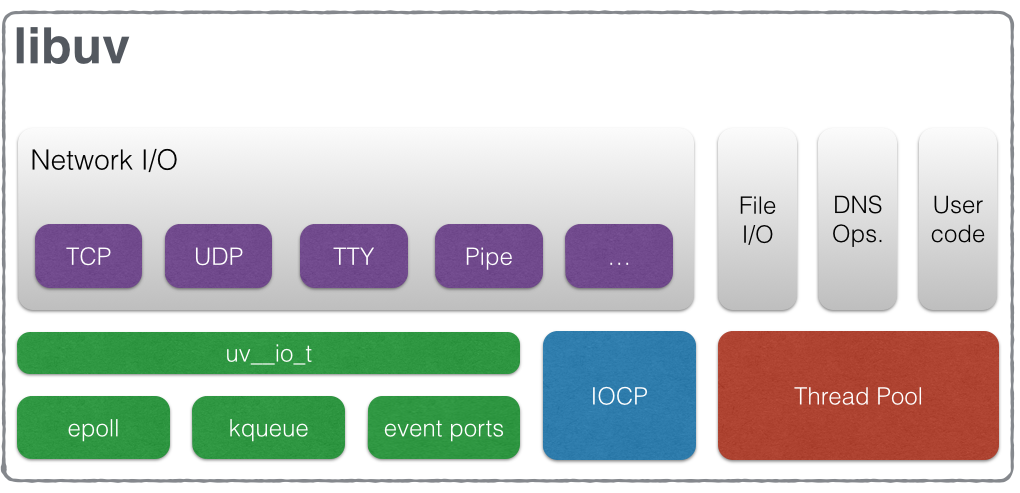
libuv的核心是事件循环(evevt loop),用户只需要注册事件处理例程(event handlers),即回掉函数(callback functions),然后运行循环(loop)。

基于libuv实现的事件驱动(event-driven)服务,在单线程中并发处理所有客户端,服务逻辑通过一系列的回掉函数实现,如果回掉函数的操作需要花费大量时间,会阻塞整个事件循环(event loop),所以长时间运行的回掉函数是一大禁忌。
但是有些回掉操作确实需要花费大量时间,就需要将阻塞调用(blocking calls)转换成异步调用(asynchronous calls),即利用线程池,libuv提供了相应的机制。
Redis
最后作者以Redis为例,分析了其并发实现。Redis实现了自己的事件驱动库(event-driven library),叫ae,既然有现成的libuv,为什么还要自己实现ae呢?Redis作者回答说,ae只有区区1K行左右的代码,专门为Redis设计,和Redis协同发展,只包含Redis需要的功能,而libuv有26K的代码,庞大又复杂,包含了很多Redis不需要的功能。这也为软件项目中的依赖处理提供了借鉴。